NLP for Question Answering
Question Answering in a Nutshell
Question Answering là tương tác giữa người và máy để trích xuất thông tin từ dữ liệu bằng các truy vấn NLP.
Hệ thống QA nhận các câu hỏi ở dạng ngôn ngữ tự nhiên.
E.g. Google search:
Designing a Question Answerer
Hệ thống QA xử lý các truy vấn bằng NLP và đưa ra câu trả lời ngắn gọn.
Một hệ thống QA được thiết kế phụ thuộc phần lớn vào ba yếu tố chính:
- Kiến thức cung cấp cho hệ thống
- Loại câu hỏi hệ thống có thể trả lời
- Cấu trúc của dữ liệu hỗ trợ hệ thống
Domain
Hệ thống QA hoạt động trong một miền. Phụ thuộc vào data được cung cấp cho hệ thống. Miền đại diện cho tất cả dữ liệu mà hệ thống có thể biết.
Hai mô hình miền:
- Miền đóng: có phạm vị hẹp và tập trung vào một chủ đề cụ thể
- **Miền mở: ** có thể trả lời các câu hỏi kiến thức chung
Question Type
Khi đã quyết định phạm vi kiến thức mà hệ thống QA bao gồm, phải xác định loại câu hỏi mà nó có thể trả lời. Phần lớn tất cả các hệ thống QA đều trả lời các câu hỏi thực tế: ai, cái gì, ở đâu, khi nào và bao nhiêu. Nhưng câu hỏi này có xư hướng đủ đơn giản để máy hiểu và có thể được xây dựng trực tiếp trên structural database, cũng như trích xuất trực tiếp từ văn bản phi cấu trúc.
Ngoài ra, còn cho phép hệ thống QA trả lời các câu hỏi giả định, nguyên nhân, xác nhận (có/không) và câu hỏi suy luận.
Implementation
Các thuật toán QA được phát triển để khai thác thông tin từ một trong hai mô hình:
- Hệ thống dựa trên tri thức cho dữ liệu có cấu trúc
- hệ thống dựa trên truy xuất thông tin cho dữ liệu (văn bản) phi cấu trúc.
Knowledge-Based Systems
Một lượng lớn data được gói gọn trong các định dạng có cấu trúc ví dụ như Structural database.
Mục tiêu của các hệ thống AQ này là ánh xạ các câu hỏi tới các thực thể có cấu trúc thông qua các thuật toán phân tích cú pháp ngữ nghĩa (semantic parsing algorithms)
Chuyển đổi văn bản thành ngôn ngữ logic hoặc ngôn ngữ truy vấn e.g. SQL

Information Retrieval-Based Systems: Retrievers and Readers
Hệ thống dựa trên truy xuất thông tin (IR QA) tìm và trích xuất một đoạn văn bản từ một collection lớn các tài liệu. Collection có thể rộng như toàn bộ web (miền mở) hoặc cụ thể như tài liệu Confulence của công ty (miền đóng). Các hệ thống IR QA hiện đại trước tiên xác định các tài liệu phù hợp trong collection, sau đó trích xuất câu trả lời từ nội dung của collection đó.
E.g. Google search:
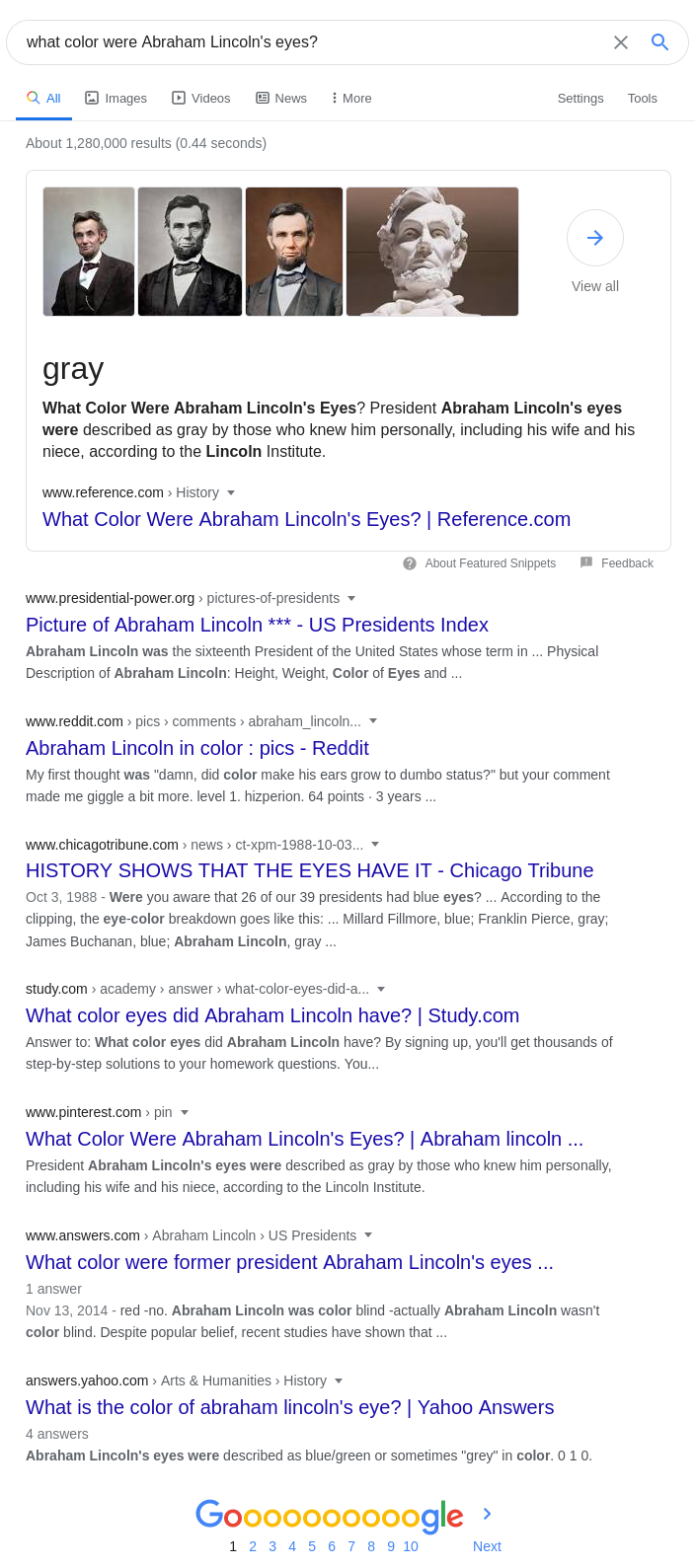
Snippet box hoạt động giống như một hệ thống QA. Các kết quả tìm kiếm bên dưới minh họa lý do hệ thống IR QA có thể hữu ích hơn so với công cụ tìm kiếm thông thường. Google search trả về nhiều liên kết khác nhau Study.com , reddit, yahoo,... nhưng không đưa ra đủ câu trả lời rõ ràng. Với snippet box ở trên cùng người dùng sẽ thấy được câu trả lời ngay lập tức mà không cần phải kiểm tra từng liên kết.
Hệ thống IR QA không chỉ là các công cụ tìm kiếm sử dụng các thuật ngữ ngôn ngữ tự nhiên chung và cùng cấp các danh sách các tài liệu liên quan. Các hệ thống IR QA thực hiện một lớp xử lý bổ sung trên các tài liệu phù hợp nhất để đưa ra câu trả lời rõ ràng dựa trên nội dung của các tài liệu đó.
Sơ đồ hệ thống QA thông thường:
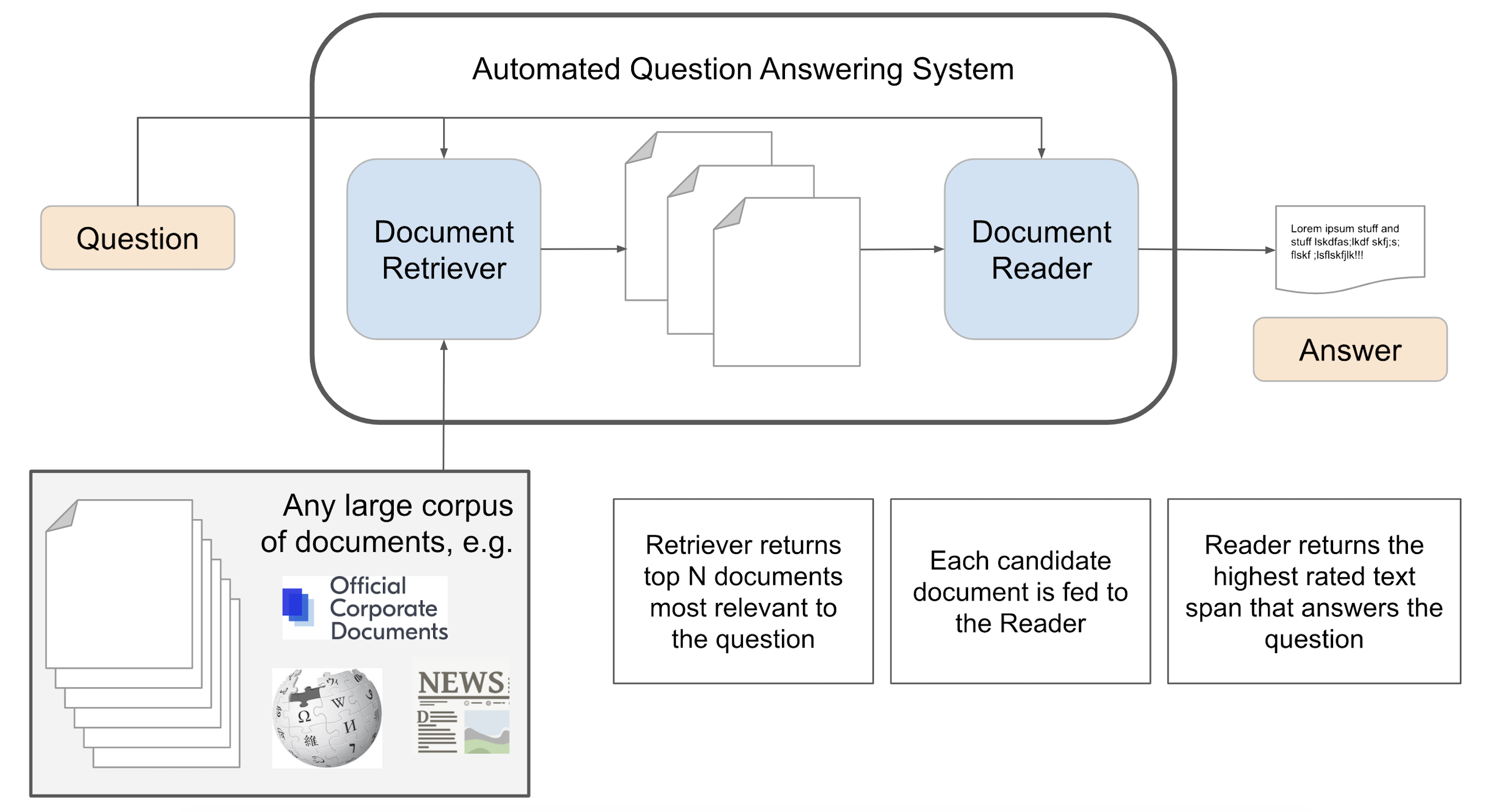
Hệ thống QA gồm 2 thành phần chính:
- Trình truy xuất tài liệu (document retriever)
- Trình đọc tài liệu (document reader)
Document retriever function giống như một search enigne, xếp hạng và truy xuất tài liệu liên quan mà nó có quyền truy cập. Nó cung cấp một bộ tài liệu liên quan có thể trả lời câu hỏi.
Document reader bao gồm các thuật toán đọc hiểu được xây dựng bằng các kỹ thuật NLP cốt lõi. Thành phần này xử lý các tài liệu liên quan và trích xuất từ một trong số chúng một đoạn văn bản rõ ràng đáp ứng tốt nhất truy vấn.
Document Retriever
Truy xuất tài liệu gồm 2 việc chính:
- Xử lý câu hỏi để sử dụng trong công cụ IR
- Dùng truy vấn IR để truy xuất các tài liệu và đoạn văn phù hợp nhất.
Xử lý truy vấn có thể đơn giản là đưa toàn bộ câu hỏi vào search engine hoặc với câu hỏi dài, phức tạp truy vấn sẽ được xử lý thông qua các kĩ thuật như bỏ qua stop word, chuyển đổi n-gram, trích xuất thực thể được đặt là từ khóa.
Vài hệ thống trích xuất thông tin theo ngữ cảnh từ truy vấn. Ví dụ: trọng tâm của câu hỏi và loại câu trả lời dự kiến, sau đó sử dụng document reader trong giai đoạn trích xuất câu trả lời.
Trọng tâm của câu hỏi là chuỗi trong truy vấn. Loại câu trả loài là phân loại câu hỏi (người, địa điểm, thời gian, v.v.)
Ví dụ:
"When was Linh hired?" Trọng tâm sẽ là "when" và loại câu trả lời có thể là data-time dạng số.
Truy vấn IR sẽ được chuyển đến một thuật toán IR. Các thuật toán này tìm kiếm trên toàn bộ tài liệu thường sử dụng kết hợp standart TF-IDF cosin để xếp hạng tài liệu theo mức độ liên quan. Việc triển khai đơn giản nhất sẽ chuyển n tài liệu có liên quan nhất đến document reader để trích xuất câu trả lời nhưng điều này cũng có thể được thực hiện phức tạp hơn bằng cách chia tài liệu thành các đoạn hoặc đoạn tương ứng và lọc chúng (dựa trên named entity matching hoặc answer type) để thu hẹp số lượng đoạn được gửi tới document reader.
Document Reader
Dựa trên các tài liệu hoặc đoạn văn có liên quan để trích xuát câu trả lời. Mục đích duy nhất của document reader là áp dụng thuật toán đọc hiểu cho các đoạn văn bản để trích xuất câu trả lời. Các thuật toán reading comprehension có 2 loai phổ biến: feature-base và neural-based.
Feature-based có thể bao gồm rule-based templates, regex pattern maching, hoặc một bộ NLP model được thiết kế để các định các feature cho phép một supervised learning algorithm xác định một đoạn văn bản chứa câu trả lời. Loại thuật toán này hoạt động toán khi câu trả lời ngắn và ở phạm vi hẹp
Neural-based tận dụng ý tưởng rằng câu hỏi và câu trả lời giống nhau về mặt ngữ nghĩa. Thay vì dựa vào từ khóa, các phương pháp này sử dụng bộ dữ liệu mở rộng cho phép mô hình tìm hiểu các semantic embedding cho câu hỏi và đoạn văn. Similarity function trên các embedding cung cấp câu trích xuất câu trả lời.
Các hôm hình neural network hoạt động tốt trong lĩnh vực này là Seq2Seq và Transformers. Đặc biệt kiến trúc Transformer hiện đang cách mạng hóa toàn bộ lĩnh vực NLP. Các mô hình được xây dựng dựa trên kiến trúc này gồm BERT (v.v. its alternative RoBERTa, ALBERT, distilBERT), XLNet, GPT, T5, v.v các mô hình này cùng sự tiến bộ về sức mạnh tính toán và
transfer learning từ các bộ unsupervised learning khổng lồ đã bắt đầu vượt trội so với con người trên một số tiêu chuẩn NLP chính, bao gồm cả QA.
Trong mô hình này người ta không cần xác định loại câu trả lời, các parts of speech, hay proper nouns.
Người ta chỉ cần đưa câu hỏi và đoạn văn vào mô hình và chờ câu trả lời. Tuy nhiên nó cũng có những hạn chế. Khi mô hình không hoạt động, việc xác định vấn đề không phải lúc nào cũng đơn giản. Khó triển khai...
Building a Question-Answerer
Sử dụng phương pháp Retrieval Document và Reader Document